Figure 2: Transformed code fragment for a hypothetical volume
visualization program transformed to off-load expensive volume
visualization rendering to a GLR server, then displaying the resulting
image on a low-end workstation. Note that full RGB image data is read back,
instead of only luminance.
To test GLR's implementation, several sample GLR clients were
implemented. The most elaborate is a GLR version of Brian Cabral's
volren real-time volume renderer![]() using 3D texture mapping to
view a human skull data-set. In its original form, the application must run
locally and requires RealityEngine graphics. After tuning
the GLR version, including minimizing the retrieved region and only
reading back luminance data instead of RGB (the skull volume is not
rendered in color), the application displayed the skull data-set to
an Indy connected by ethernet at 3-4 frames per second versus 10-15
frames per second for the original volren displaying locally on
the RealityEngine. This result is remarkable because high quality volume visualization is
not otherwise available on an Indy workstation. The GLR version is
limited by network transport overhead so increased network bandwidth
(like FDDI) would improve the display rate.
using 3D texture mapping to
view a human skull data-set. In its original form, the application must run
locally and requires RealityEngine graphics. After tuning
the GLR version, including minimizing the retrieved region and only
reading back luminance data instead of RGB (the skull volume is not
rendered in color), the application displayed the skull data-set to
an Indy connected by ethernet at 3-4 frames per second versus 10-15
frames per second for the original volren displaying locally on
the RealityEngine. This result is remarkable because high quality volume visualization is
not otherwise available on an Indy workstation. The GLR version is
limited by network transport overhead so increased network bandwidth
(like FDDI) would improve the display rate.
What are the essential modifications to volren to make it utilize GLR? The original volren has a redraw routine functionally equivalent to:
glXMakeCurrent(onyx_display, window, context); renderVolume(); glXSwapBuffers(onyx_display, window);The renderVolume routine executes the expensive volume visualization rendering algorithm using sophisticated OpenGL extension routines for 3D texture mapping. To off-load this rendering algorithm to a GLR server, the code would be transformed as shown in Figure 2.
The code assumes a GLR session has been established to a high-end GLR server capable of executing the renderVolume via accelerated hardware. The transformed code uses GLR render intervals to execute renderVolume and read back the resulting frame buffer image with glReadPixels. In the case of an expired render interval, the render is retried (with a hopefully better estimated duration interval) until it succeeds. The successfully retrieved image is then displayed on the low-end workstation by calling glDrawPixels. As an optimization, the image is only re-rendered using a GLR render interval if the scene has changed since the last image rendered.
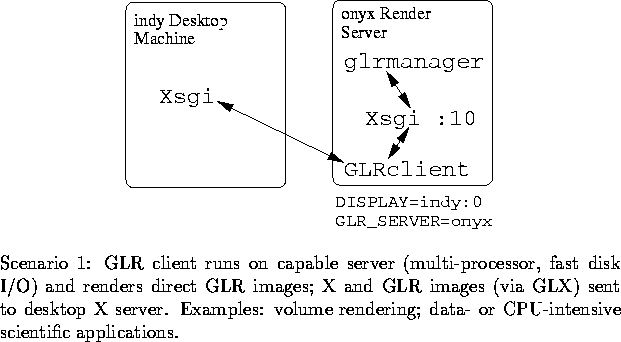
Because of the disk bandwidth and host-to-RealityEngine bandwidth required, and the multiprocessing requirements of volren, the GLR version runs on the Onyx, but displays to the Indy as shown in Scenario 1.
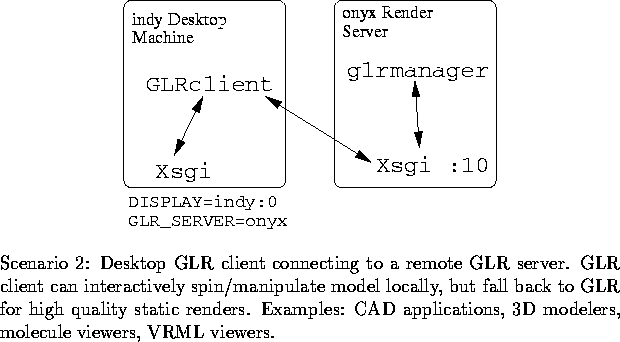
GLR is flexible as to where the GLR application can run. GLR lets the application run where most efficient (on the high-end workstation in the case of volren) while still displaying to a low-end workstation. Scenario 2 displays the reverse configuration where the GLR application runs on the low-end workstation.
Using Scenario 2, a second program called glrduckpond uses Open Inventor (which renders via OpenGL) to draw a duck swimming in a pond. The user can interactively rotate the duck around the pond with the mouse. This application demonstrates a hybrid GLR application. When the duck is moved interactively, the duck is rendered on the local Indy workstation but at a coarse tessellation. When the user stops rotating the duck, the duck is re-rendered using GLR on a RealityEngine with very fine tessellation and multisampling enabled, typically in less than half a second for a 300 by 300 pixel RGB window. The resulting antialiased and highly tessellated scene could not have otherwise been rendered as quickly on an Indy. The program demonstrates how GLR off-loaded rendering can be effectively combined with local rendering to trade-off high-quality rendering with good interactivity.